1. Capture Layer
Camera and microphone inputs collected locally for low-latency, privacy-preserving processing.
Technology
The Ability-Adaptive Augmentative Communication Platform (A3CP) turns movements and sounds into communication with help from caregivers. It is built from clear, separate parts so the system can be understood, checked, and improved over time.
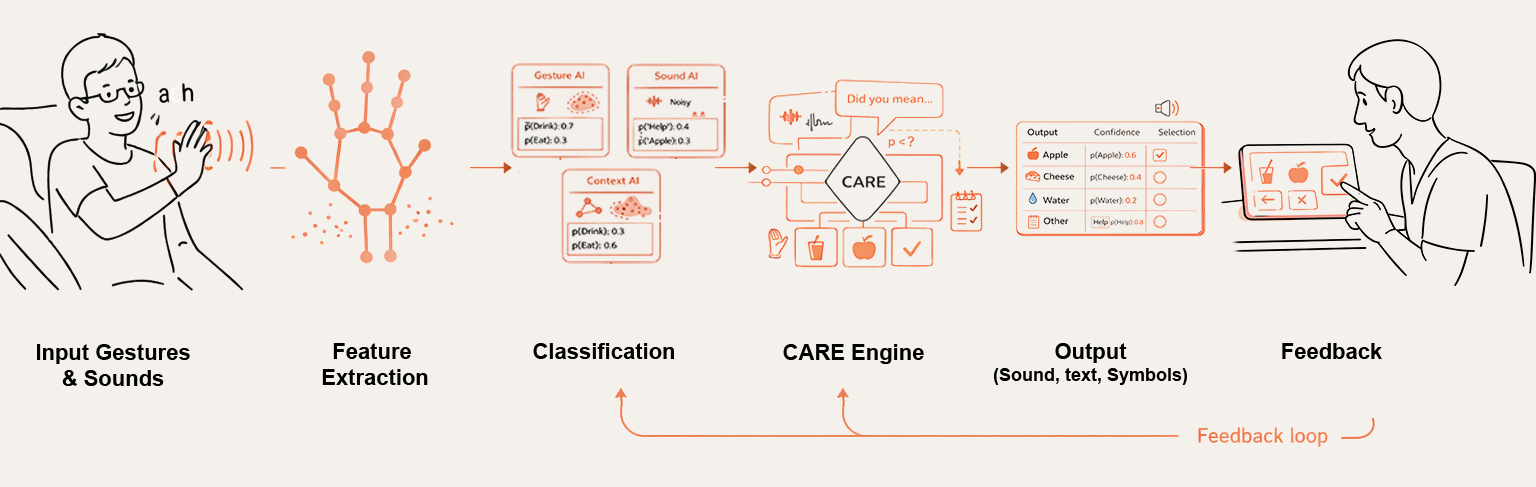
A3CP is built as a modular framework: each component operates independently and communicates through shared data standards. This makes the system easier to audit, extend, and deploy across care, therapy, and educational environments.
Camera and microphone inputs collected locally for low-latency, privacy-preserving processing.
Landmarks, movement features, and audio features converted into compact numeric vectors.
User-specific models generate intent predictions with calibrated confidence scores.
Fuses predictions, checks uncertainty, and triggers caregiver clarification when needed.
Stores caregiver-confirmed examples so the system gradually adapts to the user’s patterns.
Drives speech, text, or symbol output and can explain uncertainty or request confirmation.
Core Logic
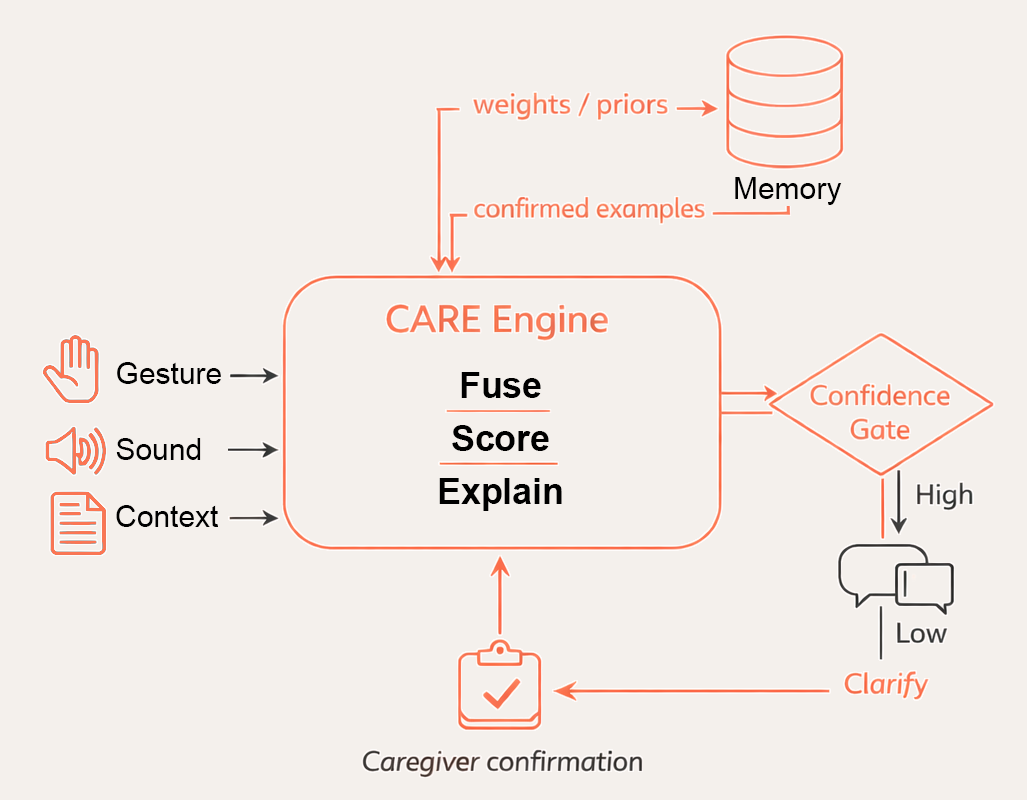
The CARE Engine (Clarification, Adaptation, Reasoning, and Explanation) is the decision core of A3CP. It combines predictions from gesture, sound, and contextual models, evaluates confidence, and determines when human clarification is required. When certainty is low, it presents plausible interpretations instead of committing to a single guess, keeping caregivers in control while enabling safe, individualized learning over time.
Deployment
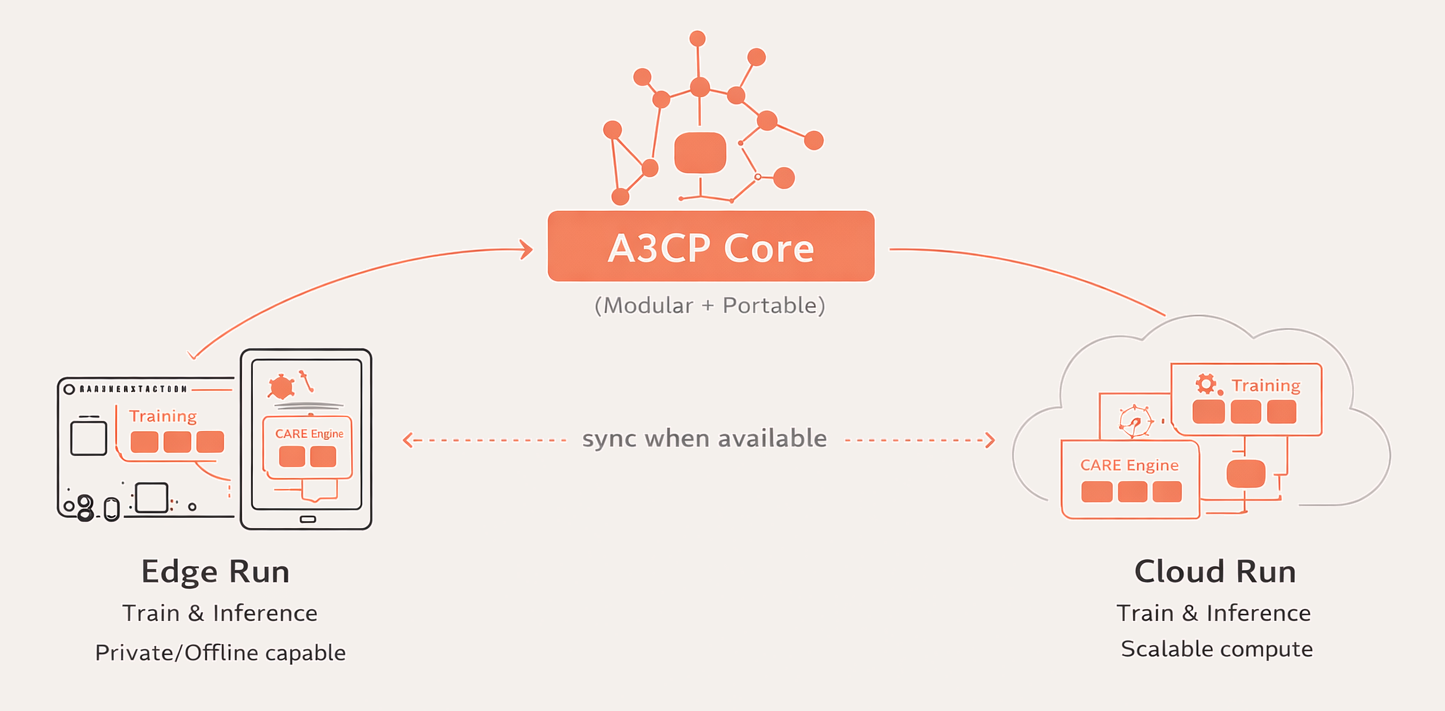
A3CP is engineered to preserve privacy, remain inspectable, and support multiple deployment modes: edge-only, cloud, or hybrid edge with optional cloud-based updating. In edge deployments, inference runs locally on affordable devices. In hybrid mode, the system can run locally while optionally synchronizing model updates or configuration changes when connectivity is available. Only derived feature data are stored — never raw video or audio — so learning and adaptation remain transparent and explainable. Code and documentation are open source, enabling independent review, replication, and improvement, and reducing vendor lock-in.
A3CP has progressed through successive prototypes toward a stable, deployable system.
Streamlit demonstrator validated feasibility of gesture capture, landmark visualization, and personalized training.
Modular FastAPI architecture established a scalable foundation for real-world deployment.
Integration of gesture and sound classifiers, caregiver-in-the-loop training, and early pilot studies.
Vision
A3CP’s adaptive architecture can support creative, therapeutic, and research applications. Because interactions can be represented as structured, interpretable data, the same pipeline that supports communication can also support learning, creativity, and longitudinal insight.
Embodied signals can be mapped to musical and visual outputs, enabling creative expression through accessible, user-specific interactions rather than conventional instruments or fine motor control.
Interpreted intent can control avatars for online communication, allowing users to choose their representation while maintaining control of meaning and interaction across distance.
The same uncertainty-aware feedback loop can support learning activities by adapting task difficulty, input mappings, and prompts to the individual, helping to learn new gestures and develop communication abilities.
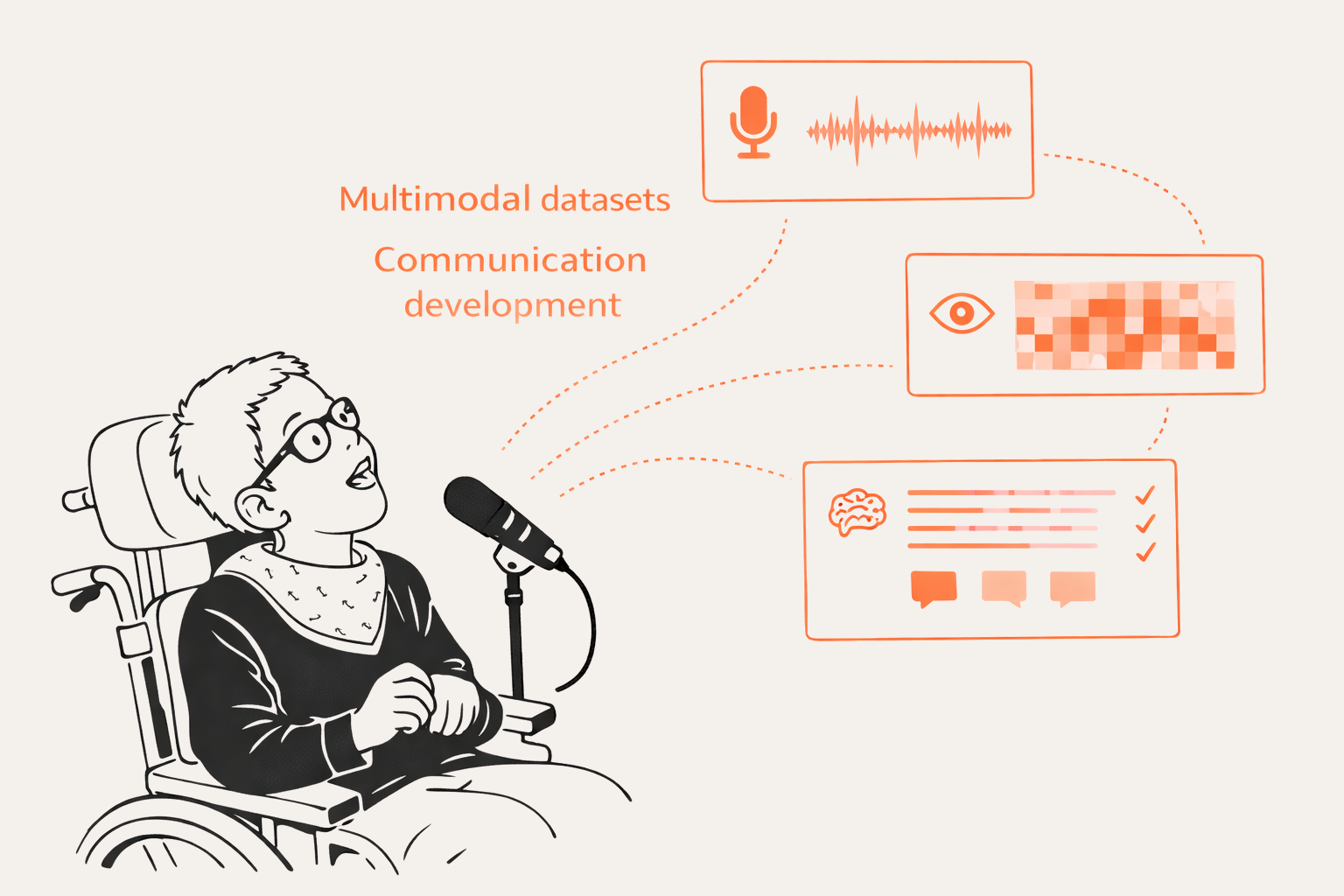
Aggregated summaries over weeks and months can support clinical review by showing trends in interaction success, uncertainty rates, and confirmed intent.
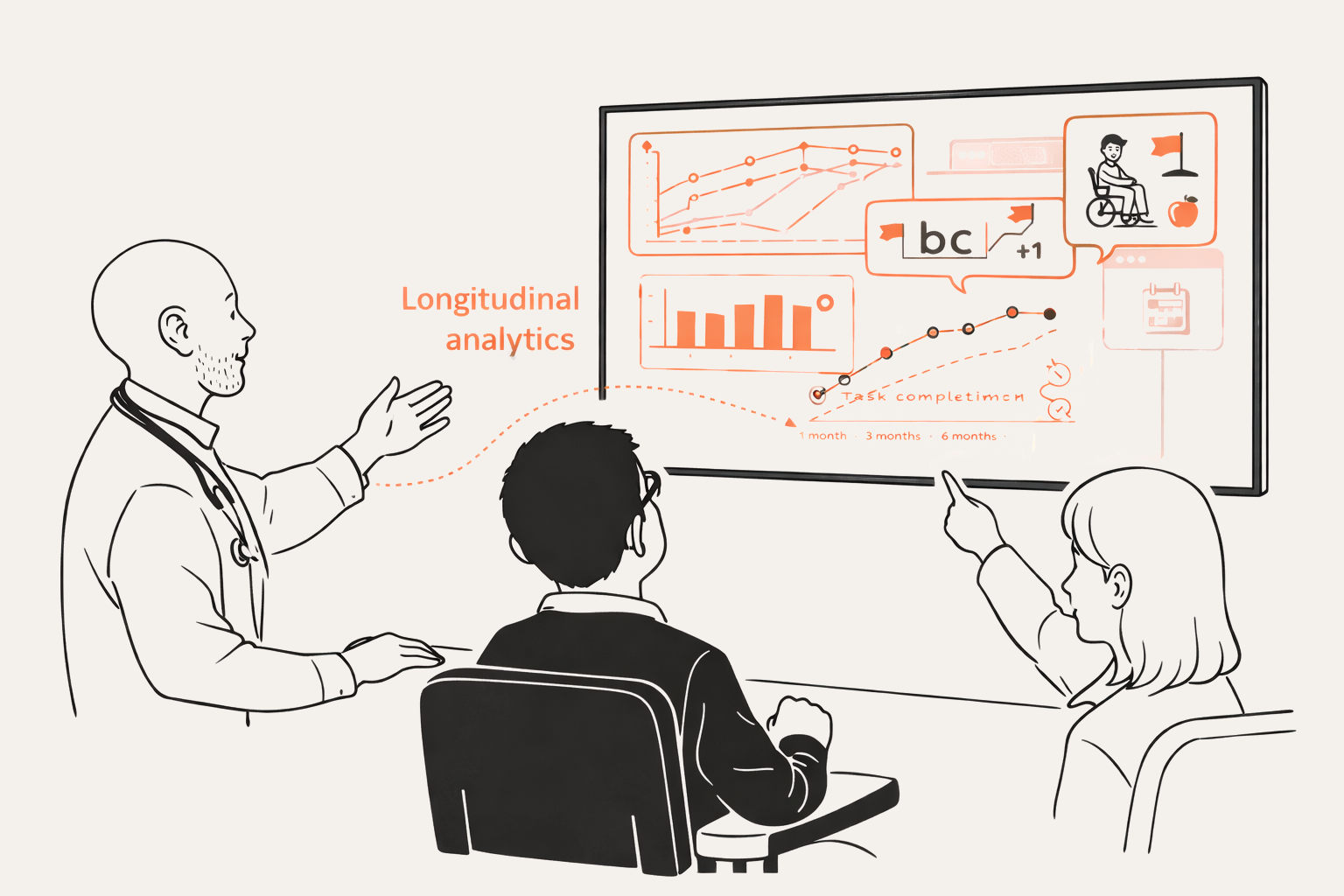
Structured traces can support research datasets that link context, model outputs, clarification outcomes, and confirmed intent, enabling studies of communication development over time.